When I bought my last property in Montreal, I did all the research myself without a buyer’s agent, made a few offers, and eventually found a place we lived in happily for 7 years.
I prefer working at my own pace — and as Freakonomics points out, realtors are fundamentally incentivized to close transactions quickly at high prices, not to find you the best deal.
That said, realtors do bring real value: filtering thousands of listings down to a shortlist, acting as a buffer between buyer and seller, and navigating legal paperwork. The goal isn’t to eliminate them entirely. But how can we delay bringing one in until it actually makes sense?
The early research phase is where I believe AI can do a lot of the work.
As a fun side project during parental leave, I started building that out. In this post I’ll detail how I built it with Claude and OpenClaw.
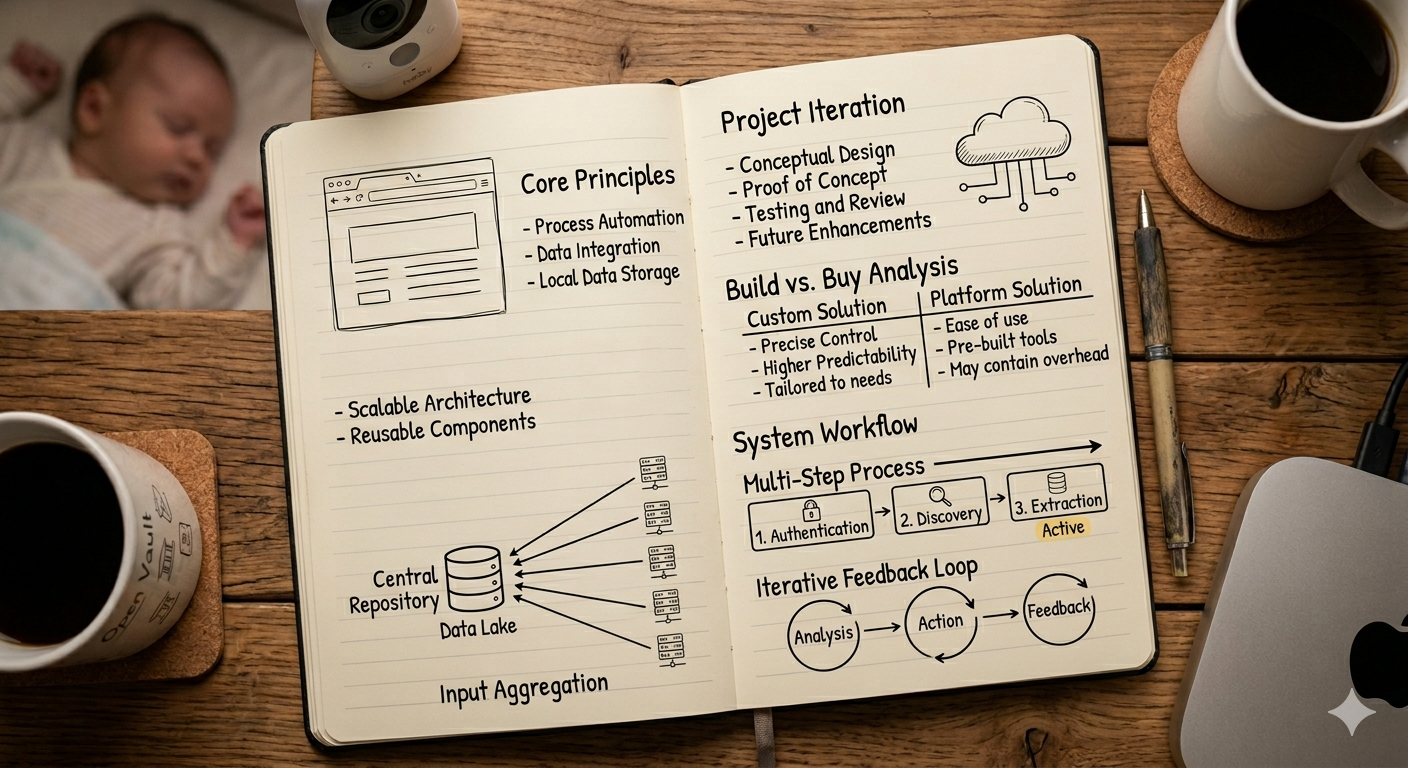
1 Architecture Overview
The following diagram shows the high-level architecture:
- Users define a search profile in plain language
- Listing data is sourced from email subscriptions as a broad initial filter
- Claude reviews each property against the profile and either flags it for human review or skips it
- Users track listings, reviews, and take notes in the UI

1.1 Sourcing Real-Estate Listing Data
The real estate industry is notoriously unfriendly to technology. Getting listing data is surprisingly hard — similar to the airline industry.
Talking to a realtor, he mentioned that in order to have access to the listing data, one must first become a licensed real estate agent. That requires training programs that can cost $20,000 or more, and access to MLS data on top of that runs around $2,000 a year. As a personal project, I don’t really want to commit to any of those.
So instead I used OpenClaw to pull publicly available listings from sources like Redfin. The idea and setup are very simple, OpenClaw runs as a daily cron job, extracting listing information from email subscriptions and storing it in a database.
1.2 Claude to Review & Match Search Profile
Initially, I let my OpenClaw agent (whose name is Lobi3) review the listings and match them against the profile. That turned out to be costly — the agent had to read through each email, click on the listing links (often with duplicates), and then read the full listing webpage before it could give an opinion on whether it was a good match.
Later I changed to passing the parsed listing data to Claude, which works a lot better in terms of token economy.
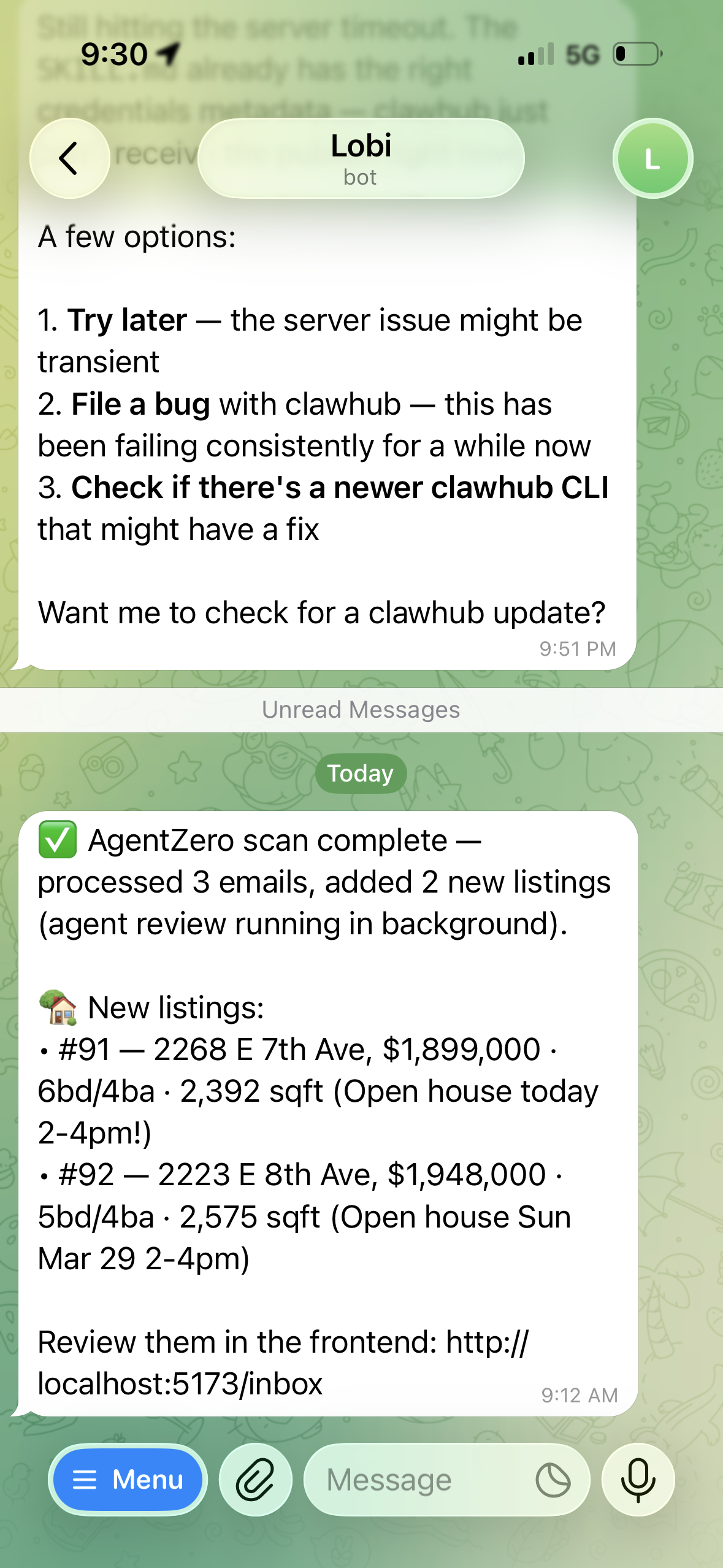
Lobi notifying me of new listings after a scan
1.3 Building A Custom UI
Previously, I tracked listings in Google Sheets, and then later Notion. I filled in the details manually, calculated the cost based on various scenarios and compared across listings.
However, neither Google Sheets nor Notion is designed for this and it was clunky to use.
Vibe coding a custom UI is a lot of joy. Any new feature that I want would just be a few prompts away.
By the end, I have a website that can:
- track basic listing info (auto filled from public data)
- allow me to one click asking Claude for his opinion
- take notes
- keep track of all delisting/relisting information
- keep track of all the images even if the property is delisted or sold
- inline map view
- a custom cost calculator that takes into consideration of downpayment, interest payment, property tax, rental income, insurance, etc.
- keep track of status of the property (buyable, interested, passed) and allow filtering
2 What Didn’t Work Well
2.1 HTML Parser
In the process, I built 4 HTML parsers for the following listing sites: Redfin, Realtor, Zillow, and REW.
It works fairly well with Redfin and REW. However, it was very fragile with Realtor and Zillow due to their bot detection logic. Even with Redfin and REW, it was not straightforward either. There is too much information to extract and each can come with various unpredictable formats.
In addition, it is not easy to handle the logic of relisting, basic information changes, deduplication across different sites, status changes, etc.
Overall, the parsing approach helped build the new listing database. It was tedious and time-consuming, I would never be able to write so many parsers in a short period of time without agentic coding.
However, it is not reliable and requires too much maintenance overhead.
2.2 Claude Needs More Context to Be Useful
On the other hand, in order for Claude’s AI opinion/review to be helpful, it would require a lot more data: such as local community information, school information, nearby sales information, etc.
I find I may be able to get more out of a simple prompt to Gemini. Because it has access to real-time data via Google Search, it can pull listing information directly from Redfin or Realtor without any HTML parsing or bot detection headaches. It would also be able to compare listings much better, give an opinion on the listing price based on other nearby similar listings, find out details about schools and their ranking, etc.
So the gap between this tool and just asking Gemini a question is still pretty big.
Summary
Building this taught me that the hard part isn’t the AI — it’s the data.
A useful property review needs far more than listing details: transit access, nearby sales, school ratings, city development plans, and more. The listing images also tell a lot about the property. That could be evaluated by running listing images through an agentic vision workflow, which is all doable, but non-trivial to build. Beyond that, much of what matters is harder to get programmatically. Things like last renovation, plumbing, electrical, roof age are often only available when you ask the seller’s agent directly.
Aggregating all of that reliably is a much bigger problem than I initially scoped. For now I’ll keep using Agent Zero as a personal bookmarking tool and will come back to this later.
Edited Apr 30, 2026.